
Explain RLHF (Reinforcement Learning from Human Feedback) in 1 minute
Byte Size Data Science

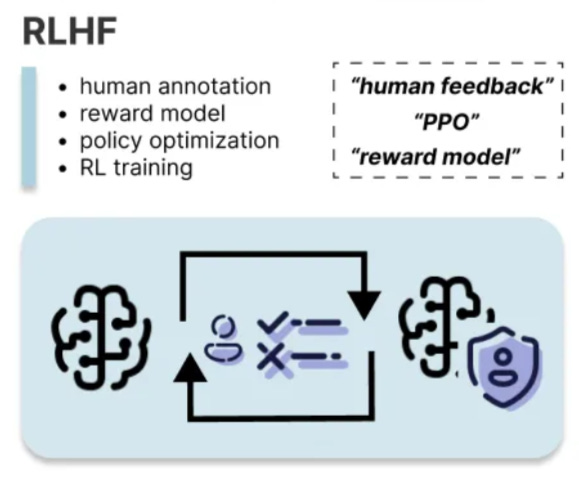
Definition
Reinforcement learning from human feedback, or RLHF, is a reinforcement learning technique that fine tunes LLMs based on human preferences. RLHF operates by training a reward model based on human feedback and using this model as a reward function to optimize a reinforcement learning policy through PPO (Proximal Policy Optimization). The process requires two sets of training data: a preference dataset for training reward model, and a prompt dataset used in the reinforcement learning loop.
Let’s break it down into steps:
Gather preference dataset annotated by human labelers who rate different completions generated by the model based on human preference. An example format of the preference dataset is
{input_text, candidate1, candidate2, human_preference}, indicating which candidate response is preferred.Train a reward model using the preference dataset, the reward model is essentially a regression model that outputs a scalar indicating the quality of the model generated response. The objective of the reward model is to maximize the score between the winning candidate and losing candidate.
Use the reward model in a reinforcement learning loop to fine-tune the LLM. The objective is that the policy is updated so that LLM can generate responses that maximize the reward produced by the reward model. This process utilizes the prompt dataset which is a collection of prompts in the format of
{prompt, response, rewards}.
Implementation
Open source library Trlx is widely applied in implementing RLHF and they provided a template code that shows the basic RLHF setup:
Initialize the base model and tokenizer from a pretrained checkpoint
Configure PPO hyperparameters
PPOConfiglike learning rate, epochs, and batch sizesCreate the PPO trainer
PPOTrainerby combining the model, tokenizer, and training dataThe training loop uses
step()method to iteratively update the model to optimized therewardscalculated from thequeryand modelresponse
# trl: Transformer Reinforcement Learning library
from trl import PPOTrainer, PPOConfig, AutoModelForSeq2SeqLMWithValueHead
from trl import create_reference_model
from trl.core import LengthSampler
# initiate the pretrained model and tokenizer
model = AutoModelForCausalLMWithValueHead.from_pretrained(config.model_name)
tokenizer = AutoTokenizer.from_pretrained(config.model_name)
# define the hyperparameters of PPO algorithm
config = PPOConfig(
model_name=model_name,
learning_rate=learning_rate,
ppo_epochs=max_ppo_epochs,
mini_batch_size=mini_batch_size,
batch_size=batch_size
)
# initiate the PPO trainer with reference to the model
ppo_trainer = PPOTrainer(
config=config,
model=ppo_model,
tokenizer=tokenizer,
dataset=dataset["train"],
data_collator=collator
)
# ppo_trainer is iteratively updated through the rewards
ppo_trainer.step(query_tensors, response_tensors, rewards)
RLHF is widely applied for aligning model responses with human preference. Common use cases involve reducing response toxicity and model hallucination. However, it does have the downside of requiring a large amount of human annotated data as well as computation costs associated with policy optimization. Therefore, alternatives like Reinforcement Learning from AI feedback and Direct Preference Optimization (DPO) are introduced to mitigate these limitations.